Two lockfiles, two philosophies 🧠 Link to heading
In the last post, I argued that lockfiles are the missing reproducibility layer.
They sit between version-controlled source code and a fully frozen computational environment. That much is shared across ecosystems.
What is not shared is the philosophy behind how the lockfile gets created in the first place.
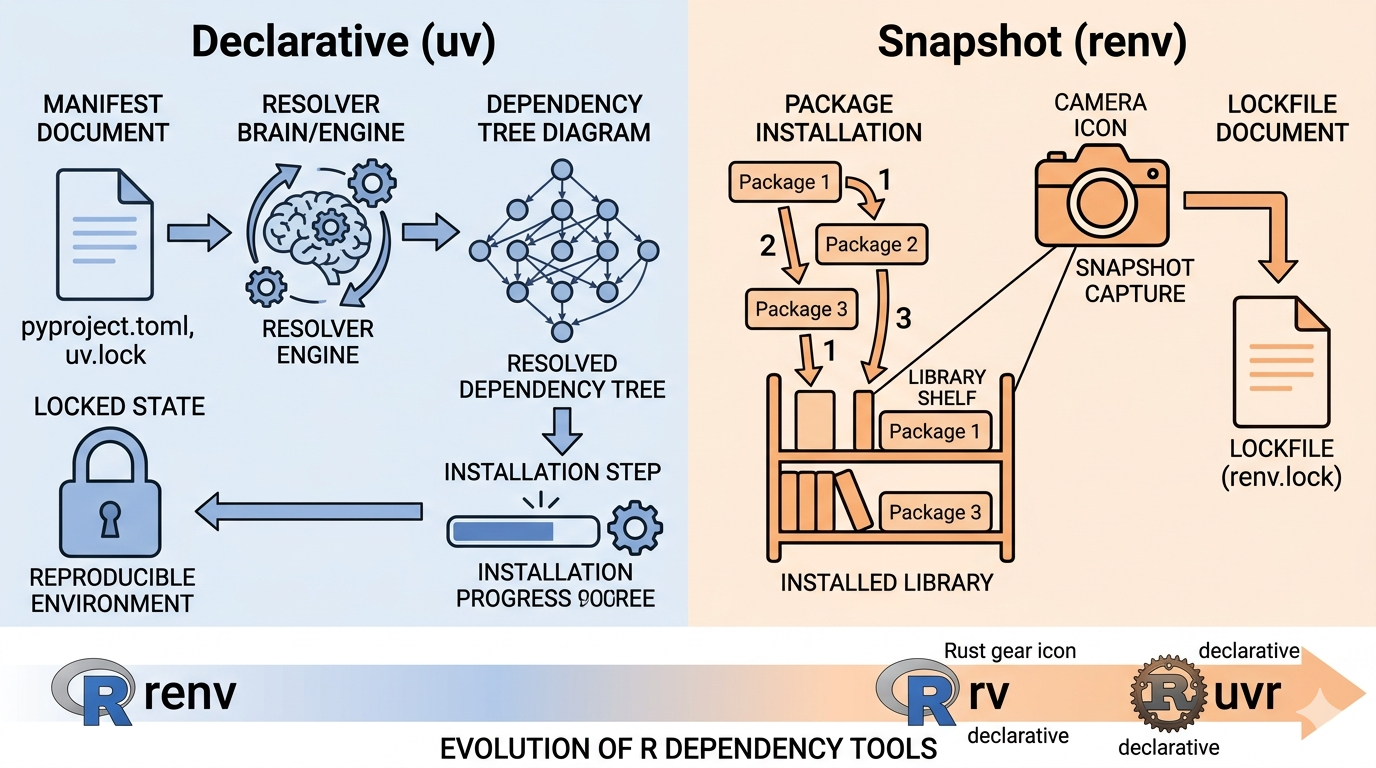
Python’s uv is declarative. You describe what you want, the resolver computes a coherent solution, and the lockfile records that solution before installation happens ⚡
R’s renv is snapshot-based. You install packages using standard R workflows, then renv records what ended up in the project library after the fact 📸
That difference sounds subtle, but it has real consequences for speed, reproducibility, cross-platform behavior, and day-to-day workflow.
uv.lock in practice 🐍
Link to heading
uv has become the default recommendation for serious Python project management for a reason.
It handles dependency resolution, virtual environments, package installation, and Python version management in one tool. More importantly, it resolves the full environment up front.
When you run uv add scanpy, uv does not simply install one package and hope for the best.
It reads your pyproject.toml, resolves the entire dependency graph, checks for a mutually compatible set of versions, and only then writes the result to uv.lock and installs anything.
That means the lockfile is part of the plan, not just a record of what happened.
Some practical consequences:
- a full dependency tree is resolved as one coherent unit
- the lockfile is suitable for deterministic rebuilds
- cryptographic hashes help verify package integrity
- one lockfile can support multiple operating systems and Python versions
- Python version management is built into the same workflow
The experience this creates is very clean:
uv add ...updates declared dependenciesuv lockrefreshes the locked solutionuv syncreproduces the environment from the lockfileuv sync --frozenenforces the lockfile as the source of truth
This is why uv feels so robust in collaborative projects and CI pipelines. The environment is resolved before installation, not inferred after installation.
renv.lock in practice 📊
Link to heading
renv solved a huge problem for R.
Before renv, many R users installed everything into one global library and hoped package drift would not break old projects. renv introduced project-local libraries, a shared cache, and a lockfile workflow that made R reproducibility much more realistic.
The normal workflow looks like this:
- run
renv::init() - install packages using
install.packages(),BiocManager::install(), orpak::pak() - snapshot the resulting state with
renv::snapshot() - restore later with
renv::restore()
That approach is pragmatic and widely adopted. It fits naturally into the way most R users already work.
But the philosophical difference matters: the lockfile is created after packages have already been installed.
In other words, renv.lock is a record of the library state, not a fully declarative plan that had to be validated up front.
That gives renv several strengths:
- strong adoption across the R ecosystem
- natural support for CRAN, Bioconductor, GitHub, and other sources
- a readable JSON lockfile
- efficient reuse through the shared package cache
- low friction for existing R workflows
It also creates some real limitations:
- compatibility is not resolved globally before installation
- cross-platform restoration can be less predictable
- R version management is outside
renv’s scope - package installation speed still depends heavily on standard R tooling
- there is no equivalent of
uv’s built-in hash-focused verification model
None of that makes renv bad. It just means it is solving reproducibility with a different architecture.
The core difference: plan vs record 🔍 Link to heading
If you remember one distinction from this post, make it this:
uv.lock: a resolved planrenv.lock: a captured record
uv says, “Here is the full environment we know is mutually compatible. Now install it.”
renv says, “Here is the environment that ended up in this library. We can try to recreate it later.”
That difference shapes everything else:
- Speed:
uvoperates in a different performance class - Determinism:
uvis stricter about reproducing one exact solution - Version management:
uvalso manages Python itself;renvdoes not manage R - Cross-platform behavior:
uvis designed for broader multi-platform locking - Workflow feel:
uvis declaration-first;renvis snapshot-first
For many R users, that last point is the most important. renv feels familiar because it does not force you to rethink how you install packages. uv feels powerful because it asks you to make the environment explicit from the start.
How R is catching up ⚙️ Link to heading
This is where things get interesting.
The R ecosystem is not standing still. Newer tools are clearly moving toward the declarative model that made uv such a leap forward in Python.
rv
Link to heading
rv is one of the clearest examples of this shift.
Instead of installing packages first and snapshotting later, rv lets you declare dependencies up front, resolve them as a whole, and sync the environment in a more uv-like way.
That matters because it closes renv’s biggest conceptual gap: the separation between package installation and coherent dependency resolution.
uvr
Link to heading
uvr pushes even further by explicitly aiming at a “uv for R” experience.
The most important idea here is not branding. It is convergence.
R users increasingly want:
- declarative dependency management
- project-level isolation
- reproducible lockfiles
- version pinning for R itself
- a fast CLI-native workflow
That is exactly the direction uvr is trying to serve.
pak
Link to heading
pak is not a lockfile tool, but it still matters in this conversation.
Many R users combine pak with renv because pak makes installation faster and more ergonomic while renv handles the environment record.
That pairing works well today, even if it does not fully change the underlying snapshot philosophy.
Practical recommendations 🧭 Link to heading
If you are starting a new Python project, use uv.
That is the straightforward choice in 2026. It is fast, declarative, cross-platform aware, and built around modern project metadata from the start.
If you are working in R today, renv is still the safe default.
It is widely used, well understood, and integrates cleanly with real-world Bioconductor workflows. If you need something stable right now, renv is still the answer for most projects.
If you are starting a fresh R project and are comfortable trying newer tooling, keep a close eye on rv and uvr.
They represent where R dependency management is heading, not just what it has been.
My practical take is simple:
- Python: use
uv - R today: use
renv - R tomorrow: watch
rvanduvrclosely
The bigger picture 🤝 Link to heading
The most important story here is not “Python won” or “R is behind.”
The important story is convergence.
Both ecosystems are moving toward the same idea:
- environments should be explicit
- lockfiles should be normal
- dependency resolution should be reproducible
- setup should not depend on memory, luck, or whatever happened to be installed that day
That is a very good direction for bioinformatics, where analyses live longer than most software tutorials and where reproducibility failures are often discovered months after the original work.
Code captures logic 🧠
Lockfiles capture environment 🏗️
And the tooling is finally catching up to that reality.